The curious case of Java String HashCode

Introduction
I have been programming in Java since the past 1.5 years. Recently, I was experimenting with performance analysis of Java Data structures. To get my hands dirty, I decided to play around with my favourite data structure i.e HashSet. HashSet provides an O(1) lookup and inserts time. I measured & compared the time taken to lookup random strings having different sizes in a HashSet.
Following is the code snippet that was written by me:-
Let’s have a look at the performance of the lookup done for random strings:-

We come across an interesting observation. The first & the last string lookup (highlighted in red) takes almost 3x to 4x time than the middle three strings. Even though the length of the middle three strings is more, still the lookup is far more efficient. This implies HashSet lookup is independent of the string’s length.
To understand this unusual behaviour of HashSet, let’s get back to the basics and understand the fundamentals.
HashSet- Internal Working
Java HashSet internally uses an array of lists to perform an O(1) insertion, lookup and deletion. HashSet first calculates the hash of the object to determine the array index where the object will be stored. Later, the object is stored at the calculated index. The same principle is applied during lookup & deletion.
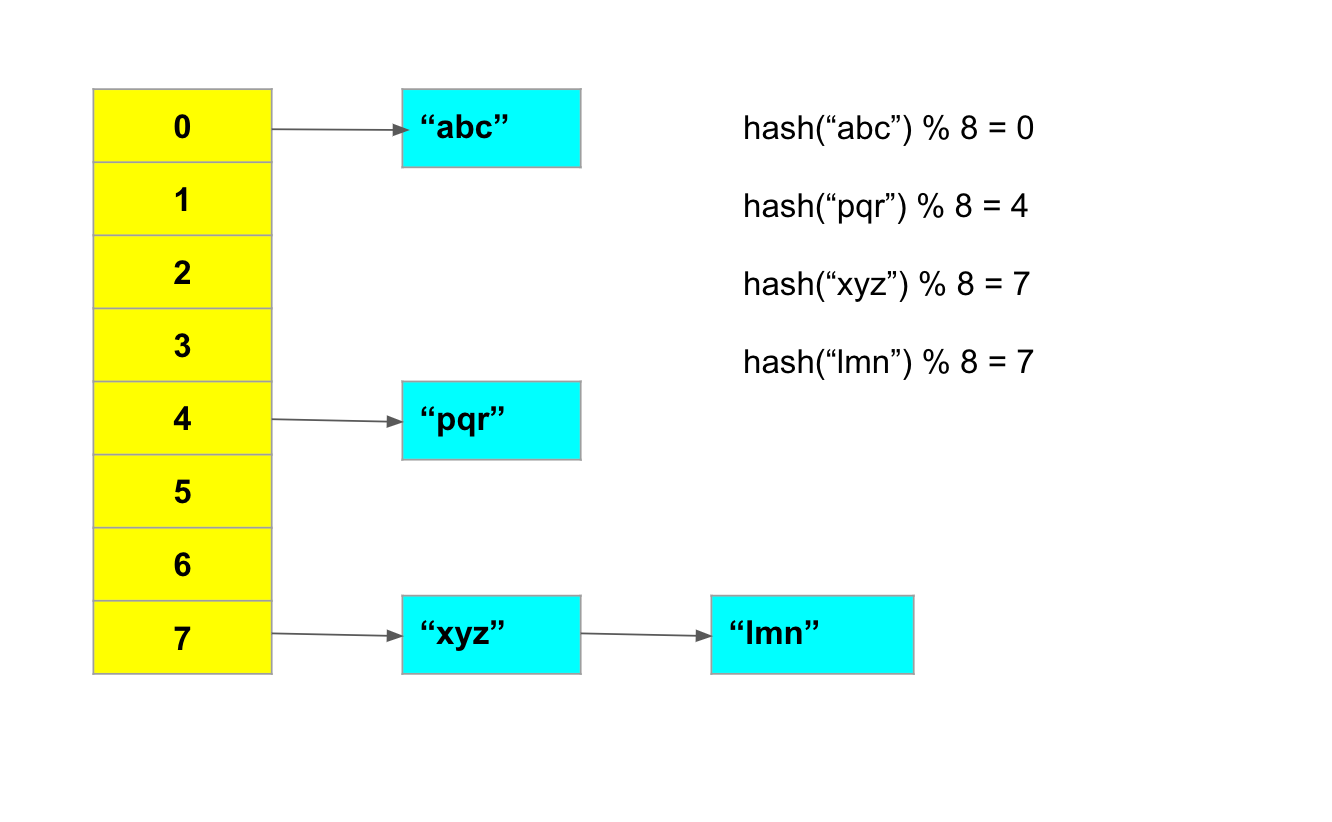
Accessing an array element is O(1) operation, so the only overhead is calculating the hash of the object. Hence, the hash function needs to be optimal to avoid any performance impact.
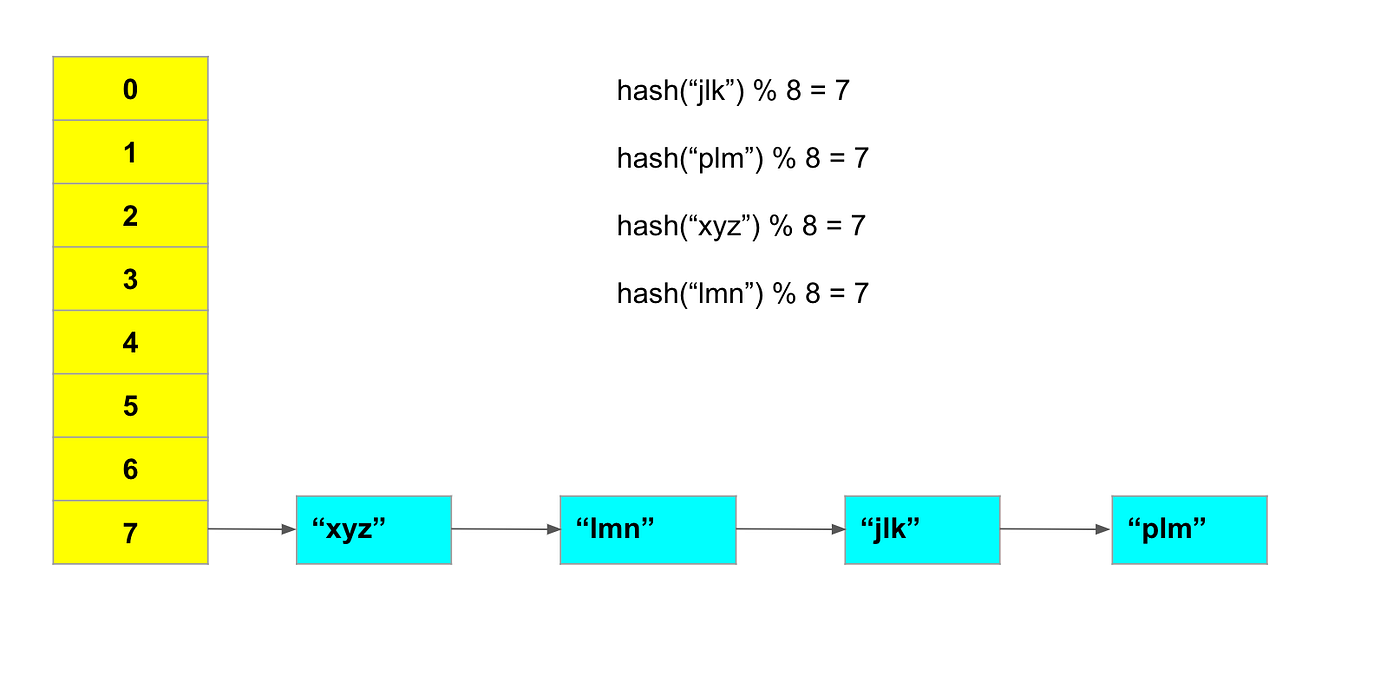
Furthermore, the output of the Hash function should have a uniform distribution. In case of collisions, the length of lists at a given index will keep growing and worst-case complexity will become O(n).
HashCode Design
In Java, every object has a hashCode() function. HashSet invokes this function to determine the object index. Let’s revisit the example where were analysing the performance of string lookup and see the value of hashCodes for the random strings.
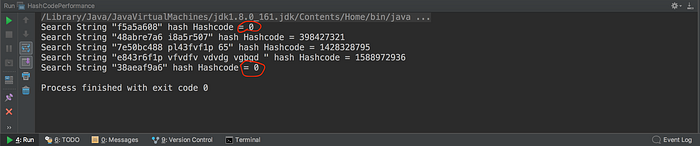
We can see that the outlier strings have hashCode as 0. Now, its time to dig into some code & glance at the implementation.
In the older versions of JDK 1.0+ and 1.1+, hashCode function for strings sampled every nth character. The downside of this approach was many strings mapped to the same hash and resulted in collisions.
In Java 1.2, the below algorithm is used. This is a bit slow but helps in avoiding collisions.
Calculation of String’s HashCode
It can be seen from the above code that when hashCode is called for the first time, the default value of the variable hash will be 0 and line 3–9 will be executed. Subsequent calls to hashCode() will not execute line 3–9 if the hash is non-zero.
It can be inferred that the hashCode() function uses a caching approach where the hash is calculated only the first time its called and later calls will get the same calculated value.
If the hash of a string is 0, then the hash computation will be done every time the function is called. Now, it is clear why the lookup of a few strings takes more time than others.
Overcoming the performance penalty
The above HashCode computation performs poorly for strings that hash to 0. How can we optimize this?
Any CS101 student would recommend using a boolean flag that will be set after the first computation and would skip computations in the subsequent calls.
You might now be wondering why didn’t Java developers think of this optimization in the first place or why wasn’t this patched in the later releases of Java?
Why not fix HashCode?
As per the implementation, the following is the formula of the hash of any String having ’n’ characters.
hash = s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1]
here s[n] is the nth character in the string
This hash function provides uniform distribution of hash across the range of integers. It implies that the probability of a string hashing to 0 is 1 in ²³² strings.
We can think of the below cases where the string can hash to zero:-
- String only contains 0 (Unicode character)
- Empty String
- Hash code is 0 as a result of integer overflow
In real-world applications, the probability of getting such kind of strings is minuscule.
Fixing the hashCode implementation is trivial & Java developers might have thought about it. However, there is no added advantage in fixing it.
Currently, only strings that hash to 0 are impacted. Let’s say we fix the hashCode by adding a boolean. Overall, we won’t see any huge impact on the performance of a real-world system. It might result in 0.000010 % improvement in speed. It’s analogous to saying we optimized a task that could be finished in 1hr to 59 min 59 sec 7 milliseconds.
So, we are better off not making any change in the hashCode() by introducing a new variable as there is no significant speed gain.
English Strings that hash to 0
I took a list of 20k English Dictionary words and tried combining the words to check if they hash to zero. When I considered single meaningful English words, none of them hashed to zero. Combination of two or more words resulted in a zero hash.
Few are some examples of sentences (meaningful words)that hash to zero:-
- carcinomas motorists high
- zipped daydreams thunderflashes
- where inattentive agronomy
- drumwood boulderhead
HashSet or HashMaps showcase the best behaviour in getting, setting or deleting the value. However, there are cases where the performance can get impacted due to unusual behaviour.
References:-